
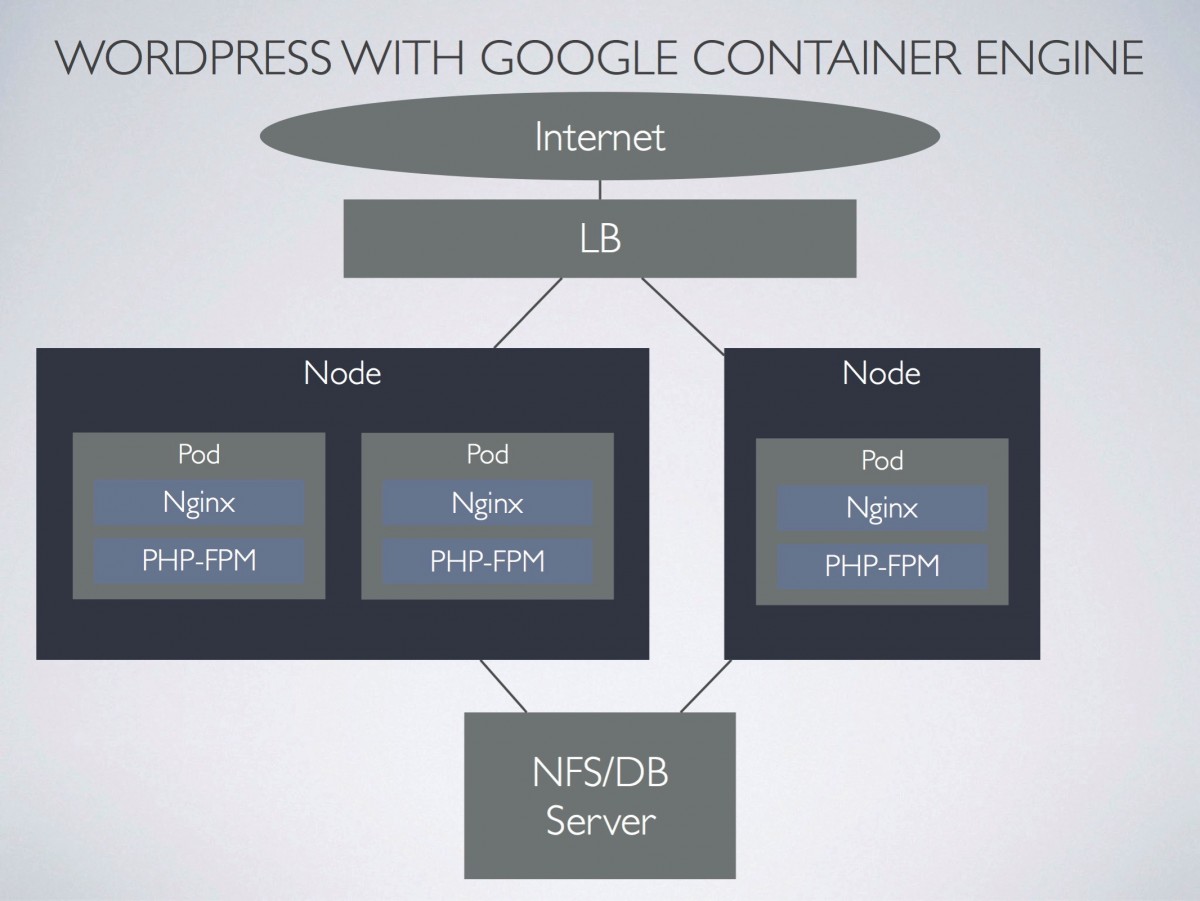

Google Container Engineのマシンをg1-small(共有vCPU1個 1.7Gメモリ)からn1-standard-1(vCPU1個 3.75Gメモリ)にアップグレードしました。
不安定なg1-smallよりn1-standardの方が安い!?
うちはGoogle Container Engineをg1-smallのスペックのマシンで稼働していました。
g1-smallだと1ヶ月$21.9なのですが、実際動かすと$43.34もの金額になっていました。
これはオートスケールの設定をしていて負荷が上がると最大4台構成になるためなのですが、g1-smallはどうも不安定らしく、しょっちゅうコンテナが全滅したり、そのせいか負荷が上がってオートスケールで台数が増えてしまっていました。
g1-smallは共有vCPUタイプなので、そこは安かろう悪かろうですが、$43となると実はひとつ上のクラスのn1-standard-1マシンが$40.15なので、こっちの方が安かったりします。
それならばということで、いっそのことn1-standard-1にグレードアップする事にしました。
無停止でマシンアップグレードのはずが…
Google Cloud Platform Japan Blogに、「ノードプールというのを使えば無停止でマシンタイプを変更できるぜ!」って記事がありました。
Google Container Engine(GKE)に追加されたノード プールの使い方
あと、こちらには具体的なコマンドも紹介されていました。
Google Container Engine で新しいノードにダウンタイムゼロで移行する – Qiita
[bash]gcloud container node-pools create [新しいノードプール名] –machine-type=[マシンタイプ] –disk-size=[ディスクサイズ] –num-nodes=[初期ノード数][/bash]
↓こんな感じで作りました。
[bash]gcloud container node-pools create standard-pool –machine-type=n1-standard-1 –disk-size=15 –num-nodes=1[/bash]
今、既に作成されているクラスタにマシンタイプやディスクサイズを変えて新しいグループを作る事が出来るんですね。ノードプールが新しく出来るとインスタンスが一つできあがります。
[bash]kubectl cordon [古いノード名][/bash]
これで指定した古いノードに新しくPodが作成されるのが止まり…
[bash]kubectl drain [古いノード名][/bash]
これで新しい古いノードに立ち上がっているポッドがさっき新しく作ったノードプールと共にできたノードに移行されていきます…のはずだったんですが、
[bash]error: pods not managed by ReplicationController, ReplicaSet, Job, or DaemonSet (use –force to override): fluentd-cloud-logging-gke-xxxxxx, kube-proxy-gke-xxxx[/bash]
こんなエラーが出て、drainコマンドがエラーになりました。説明にある通りに–forceを付けて再度実行してみると今度はうまくいった!
でも、これでやると全然無停止じゃなくて、普通にノードに繋がらなくなりました。だめじゃん(笑)
無停止ではないけど、ともかくn1-standard-1にはこれで移行できました。
安定動作
g1-smallの時は必ず一日一回Stackdriverからサイトの停止検知のメールが飛んできてたけど、n1-standardだとさすがに占有コアだからか安定してますね。
関連する記事
 Google Container Engineに移行した その4 Google Container Engineでローリングアップデート Google Container Engineに移行した その3
Google Container Engineに移行した その4 Google Container Engineでローリングアップデート Google Container Engineに移行した その3  Google Container Engineのクラスタとノードプールをアップデートする Google Container Engineに移行した その2
Google Container Engineのクラスタとノードプールをアップデートする Google Container Engineに移行した その2  Google Container Engineに移行した その5 オートスケール Google Container Engineに移行した その1
Google Container Engineに移行した その5 オートスケール Google Container Engineに移行した その1  GCEのオートスケールのテンプレートをコマンドで楽に差し替える
GCEのオートスケールのテンプレートをコマンドで楽に差し替える  WordPressがクラッキングにあってコンテンツ全消しされた
WordPressがクラッキングにあってコンテンツ全消しされた