
前回はAutoBucketを開発するに至った理由などを書いてみました。今回からはAutoBucketがどのようにして作られたか技術的なところメインに書いていきたいと思います。
前回までの記事
Thunderbirdの拡張機能を作ろう!
前回、メール消失の憂き目に遭ってしまったことを書きました。しかし、POPFileは便利だった!なんとかならないか考えた末、Thunderbirdの拡張機能で同じようなものを作れば、少なくとも通信失敗でメール消失はしないんじゃね?と思い当たりました(拡張機能で大バグあったら一緒のことになるけど…)。
拡張機能はWeb Extensionを使う
Thunderbirdの68からWeb Extension(JavaScript)という新しい仕組みが導入され、今までの拡張機能の仕組みは使えなくなりました。
https://thunderbird-webextensions.readthedocs.io/en/68/index.html#
まだまだ機能不足で例えば新着メールに対して拡張機能で何か処理をすることはバージョン68ではできません(75ぐらいからできるようになるみたいです)。
Typescritp + Vue.jsが使える!
調べてみるとWebExtensionでもTypeScriptやVue.jsが使えることがわかりました。これらが使えると効率良く開発できるので取り入れました。
Vue.jsのWebExtensionテンプレートはこちらをベースにしました。
https://github.com/Kocal/vue-web-extension
使い方の解説はこちらを参考にさせていただきました。
https://r17n.page/2019/09/03/chrome-extension-with-vue-web-extension/
これだけだとTypeScriptには対応していないので追加でTypeScript関係の設定を地道に調べながら行いました。
こちらと過去TypeSciptで開発したTaskClearを参考にトライ & エラーでなんとか環境整いました。
ソース全体はGitHubに公開しているで知りたい方はこちらをどうぞ。
https://github.com/a-tak/auto-bucket
TypeScriptはコンパイル前からいろいろエディタ上で間違い指摘してくれるから楽ですね。Java程ガチガチに型を書かなくても文脈で型推測して入力補完してくれるのも楽。
分かち書きはどうしよう
ベイジアンフィルタは単語の出現回数でメールの特徴を掴んで分類するのでメールの本文を単語毎に分割しないといけません。しかし、日本語は英語のように単語を区切りがありません。これを単語毎にわけてくれるのが「分かち書き」用のライブラリです。Kakashiなどが有名なのですが、今回はTinySegmenterと言うライブラリにしました。
http://chasen.org/~taku/software/TinySegmenter/
Kakashiなどは日本語の辞書を組み込んでそれにより文章から単語を切り出すのですが、TinySegmenterはなんと機械学習により辞書なしで分かち書きをしてくれるとのこと。変な区切れ方する場合もあるけど、今回そこまで厳密性は求めないのでこれにしました。
TypeScriptの型定義はなかったので自分で型定義ファイルは作成しました。メソッド少ないのですぐ終わりました。
https://github.com/a-tak/auto-bucket/blob/master/src/%40types/tiny-segmenter/index.d.ts
ベイジアンフィルターはsimple-statics
ベイジアンフィルターもいくつかライブラリがgithubに公開されていてnpmで簡単にインストールできます。
しかし、大半のベイジアンフィルターは日本語に対応していません。最初、日本語をいくらツッコんでも判定結果が変なので、ソースの中を見ると、ほとんどのライブラリが内部で数字とアルファベット以外を消去した後に処理してました。そりゃ結果がおかしくなるわけだ。文章中のピリオドとか記号を外して学習させたいという意図なんでしょうが、これじゃ日本語メールの解析に使えません。
いろいろ探したところsimple-statisticsというライブラリは日本語を除去しないことが分かりました。
https://github.com/simple-statistics/simple-statistics
というか、他のライブラリより原始的な動きしかしなくて、他のライブラリみたいに文章をまるごとを渡して結果を返してくれるような動きじゃなくて1単語毎渡してその単語がどの分類に入るスコアを返してくれる感じだったので、自分でスコアを合計していろいろ作り込む必要がありました。まあ、これのおかげでAutoBucketは学習のロジックをいろいろ調整できたし、どのような判定が行われたか後でログで確認できるようになったので結果良かったです。
画面はVuetify
今回、設定画面や判定結果のログ表示用に画面が必要なのでVuetifyも使いました。これも後から追加するの大変だったけどなんとか入りました。

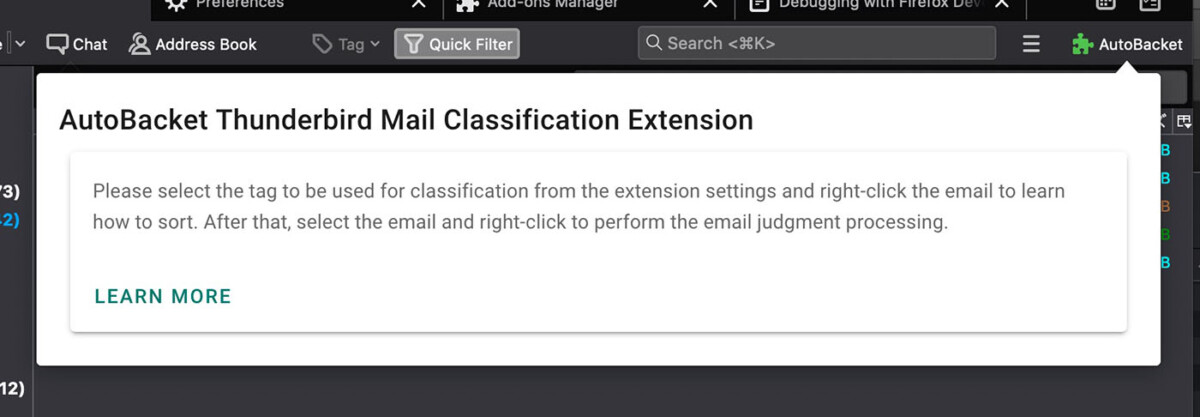
こんな感じで拡張機能の画面の中にVue.js + VuetifyのリッチなUIが出せるんですね。面白い。

WebExtensionの機能でこういうポップアップも出せる。その中身はVue.js + Vuetify。マテリアルデザインっぽいカード形式のUIを出してみた。
学習ロジックは試行錯誤
最初はメール本文をTinySegmenterにツッコんでそれをそのままベイジアンフィルターに入れてたんだけど、精度があきらかに悪い。統計取ってないので肌感だけど相当数メールを覚えさせないと意図したとおりに分類されないし、ちょっと違うメール学習させたら、また誤判定されることが多くなったり。AIとかやったことないけど、たぶんやってる人はこういう苦労してるんだろうな…と思ったり。
それでメールがどのように判定されているかを表示するログ画面を追加して状況を把握した(AutoBucketでctrl + shift + Vで表示できます)。

単語毎のスコアと出現回数を表示する画面を作った。ここのスコアが大きいほど判定結果に影響を与えていることになる。上の画面は改善後なので大分まともになっているのだけど、最初は「は」とか「が」とか1文字の助詞やスペースやマイナスなどの記号が上位に来ていた。そんな文字はどのメールにも含まれるからメールの特徴を掴むにはふさわしくない。なので、思い切って1文字だけの単語については学習対象外にした。これによりかなり判定精度があがった。
さらに文字コード指定で可能な限り記号も対象外にした。記号のみをうまく除外するというサンプルが見つからなかったので、Wikipediaのユニコードのページを見ながら地道にフィルタした。超めんどくさかった。海外のベイジアンフィルターが英数字以外をバッサリ捨ててるのも納得。
結果、学習対象はこんな感じになった。

助詞が省かれ装飾の為の記号も消えて単語だけになっている。
国際化対応(i18n)
Thunderbirdの公式アドオンページに公開したら、通りすがりのドイツ人に日本語じゃわかんねえよと星一つの評価をつけられたので英語に対応させた😀
動作確認するときはThunderbirdの設定の詳細に言語を指定するところがあるので、ここに英語を追加して適用するとよい。


Google翻訳任せなのでちゃんと伝わるかは不明。Github Pageで作成しているヘルプも日本語と英語でわけていて言語設定によって飛び先のリンクも変わるようにしている。
UIのi18n化にはvue-i18nモジュールを使い、右クリックメニューやmainfest.jsonのi18n化にはWebExtensionのi18nモジュールを使っている。
https://developer.mozilla.org/ja/docs/Mozilla/Add-ons/WebExtensions/Internationalization
そしてやっと完成
結局、開発に掛かった時間は77時間。結構かかったわー。
今回も今までやってない事ばかりいろいろ取り入れたので色んな所でひっかかった。ここに書き切れないので同じようなことをしようとしている人はGitHubにおいているソースを参考にしてください。
a-tak/auto-bucket
Automatic mail classification extension with Bayesian filter for Thunderbird – a-tak/auto-bucket
AutoBucket
メールをベイジアンフィルターで複数のバケツに分類してタグを付ける拡張機能です。
関連する記事
 メールの文面から自動分類するThunderbird拡張機能作った その1
メールの文面から自動分類するThunderbird拡張機能作った その1  メールの文面から自動分類するThunderbird拡張機能作った その2
メールの文面から自動分類するThunderbird拡張機能作った その2  ThunderbirdからPOPFileにジャンプする拡張機能作った
ThunderbirdからPOPFileにジャンプする拡張機能作った  メールを自動分類するThunderbird拡張機能にロゴつけた
メールを自動分類するThunderbird拡張機能にロゴつけた  AutoBucketに統計チャート表示機能つけた メール自動分類Thunderbird拡張機能に自動判定機能追加
AutoBucketに統計チャート表示機能つけた メール自動分類Thunderbird拡張機能に自動判定機能追加  WordPressでd3.jsのグラフィカルな投票表示プラグインを作りました
WordPressでd3.jsのグラフィカルな投票表示プラグインを作りました  ImageDividerをWindows7に対応させた
ImageDividerをWindows7に対応させた  Voting Chart 0.6公開 – 評判の悪いランキング表示対応
Voting Chart 0.6公開 – 評判の悪いランキング表示対応